
Research Data Management: understanding the data lifecycle in real research
TL;DR (30 seconds)
- Research Data Management (RDM) is about managing research data from the beginning of a project until long-term reuse.
- It is not just storage. It includes documentation, quality, privacy, preservation, and sharing.
- The RDMkit lifecycle model (ELIXIR) helps structure research work into clear phases.
- Good RDM improves reproducibility, transparency, and research impact.
Before starting: why does RDM even matter?
During the EP PerMed training at ELIXIR, I realised something important. In research, we usually focus on results. But results are only as strong as the data behind them.
Many research problems happen because:
- data is poorly documented
- folders are messy
- no one remembers how preprocessing was done
- sensitive data is not handled correctly
- results cannot be reproduced later
Research Data Management exists to reduce these risks.
What is Research Data Management?
Research Data Management (RDM) covers everything related to how research data is:
- planned
- collected
- processed
- analysed
- preserved
- shared
- reused
It is not a single task at the end of the project. It is something that should be considered from day one.
RDM connects documentation, metadata, ethics, GDPR compliance, reproducibility, and open science.
The Research Data Lifecycle (RDMkit Model)
During the training, we used the RDMkit data lifecycle model from ELIXIR.
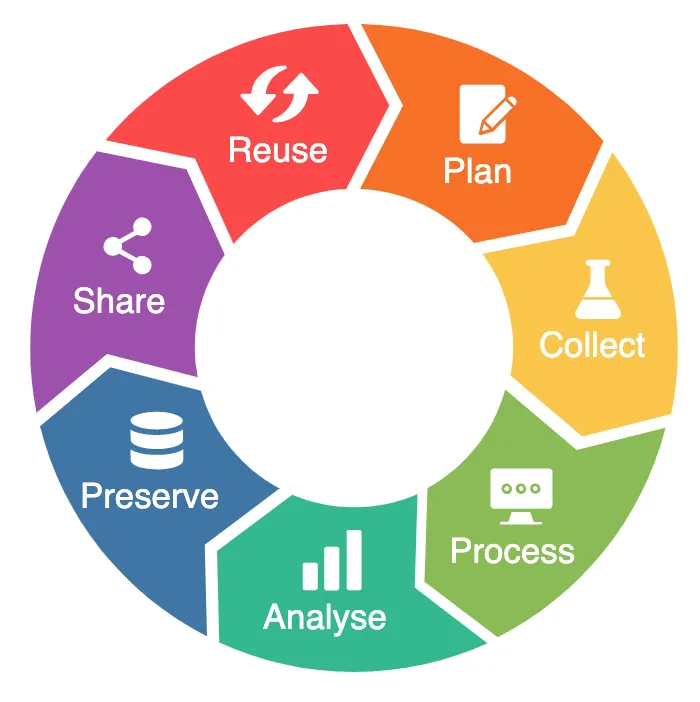
This model shows that research data moves through connected phases. It is not strictly linear. Reuse can start a new cycle.
The full framework is available here:
👉 https://rdmkit.elixir-europe.org/data_life_cycle
The lifecycle stages explained in simple terms
1) Plan
Before collecting any data, it is important to decide:
- What type of data will be generated?
- Which formats will be used?
- How will data be stored?
- How will privacy and consent be handled?
- Who will have access?
At this stage, a Data Management Plan (DMP) is often written. It should not be static. It should evolve during the project.
2) Collect
Data collection includes experiments, surveys, simulations, or observations. These are important aspects:
- Good experimental design
- Data quality (consistency, accuracy, completeness)
- Recording problems during collection
- Using electronic systems like ELN or LIMS
Metadata should be captured at this stage, not added months later.
3) Process
Raw data is rarely ready for analysis. This stage includes:
- Cleaning
- Quality control
- Transformations
- Integration of multiple datasets
- Early anonymisation for sensitive data
Every transformation step should be documented clearly.
4) Analyse
This is where insights are generated. Good practices may include:
- Documenting workflows
- Saving parameter choices
- Commenting code
- Maintaining version control
- Keeping a clear folder structure
Reproducibility depends heavily on this stage being well documented.
5) Preserve
Preservation ensures long-term usability. This includes:
- Using appropriate file formats
- Clear file naming and versioning
- Writing README files
- Backups and snapshots
- Using checksums to detect corruption
Without proper preservation, data can become unusable even if it still exists.
6) Share
Sharing data increases transparency and citation potential. The Key decisions are:
- Which repository to use
- What license to apply
- What metadata to include
- Whether access should be open or controlled
Sensitive data does not need to be fully public. It can follow controlled access rules.
7) Reuse
Reuse allows data to:
- Validate results
- Support new studies
- Be combined with other datasets
For reuse to work, data should follow the FAIR principles:
- Findable
- Accessible
- Interoperable
- Reusable
RDM and Open Science
RDM supports open science by:
- Improving reproducibility
- Reducing publication bias
- Increasing transparency
- Making data reusable beyond the original project
Good data management benefits both individual researchers and the broader scientific community.
Personal reflection
As someone doing a Master’s in Artificial Intelligence and coming from a software engineering background, I found the lifecycle approach really practical.
In software projects, we naturally think about structure, version control, documentation, and system design from the beginning. In research, however, data is often treated as something temporary, just a step toward publication.
What I learned during this training is that data should be treated like a product, not a by-product.
The lifecycle model helped me understand that every stage — from planning to reuse — affects reproducibility and long-term value. Small decisions like naming files clearly, writing metadata properly, or documenting preprocessing steps can make a huge difference months later.
Planning early saves a lot of effort later.
Resources
If you want to explore Research Data Management and the data lifecycle in more detail, these are useful references:
-
RDMkit Data Lifecycle (ELIXIR)
https://rdmkit.elixir-europe.org/data_life_cycle -
RDMkit Main Portal
https://rdmkit.elixir-europe.org/ -
FAIR Data Principles (Wilkinson et al., 2016)
https://www.nature.com/articles/sdata201618 -
Science Europe – Practical Guide to Research Data Management
https://scienceeurope.org/our-resources/practical-guide-to-the-international-alignment-of-research-data-management/
These resources are especially relevant for European research projects and for researchers working with sensitive or complex datasets.
Conclusion
Research Data Management is not just a requirement. It is a way to make research more reliable and sustainable.
The data lifecycle shows that reproducibility and reuse depend on decisions made from the very beginning of a project.
Treating data as a valuable research output improves both scientific quality and long-term impact.
Ayesha Munir — Software Engineer | Artificial Intelligence (MSc)