
Dagster: el orquestador que piensa en datos (no en tareas)
TL;DR (30 segundos)
- Dagster es un orquestador de datos open source (Apache 2.0): puedes usarlo gratis y autoalojarlo.
- Su idea clave: en vez de modelar “tareas conectadas”, modelas assets (tablas, ficheros, modelos, features) y sus dependencias.
- Lo mejor: trazabilidad (lineage) a nivel de asset, checks de calidad integrados, y una UI que ayuda de verdad a ejecutar y depurar.
- Lo menos bonito: curva de aprendizaje (nuevo modelo mental) y operación/seguridad si lo despliegas en producción por tu cuenta.
¿Es gratis? Sí. Dagster (OSS) es 100% gratuito. Dagster+ es su versión managed de pago.
Antes de empezar: ¿qué es un DAG?
Un DAG (Directed Acyclic Graph) es simplemente una forma de representar tareas con un orden y dependencias entre ellas. Imagina preparar un informe de pacientes:
[Extraer datos] → [Limpiar duplicados] → [Calcular métricas] → [Generar informe]Cada paso depende del anterior. No puedes calcular métricas si no has limpiado los datos. Eso es un DAG: pasos donde las flechas van en una dirección (sin ciclos).
Los orquestadores como Dagster, Airflow o Prefect ejecutan estos pasos en orden, reintentan si algo falla, y te avisan cuando hay problemas.
¿Por qué debería importarte Dagster?
En un equipo de datos, el objetivo real no es “que corra el DAG”, sino que el dato final sea correcto, fresco y reutilizable: customers_clean, un dataset curado, features para ML, o un informe para negocio.
Dagster se diseña alrededor de esa idea: los datos (assets) son el producto, y la orquestación existe para producirlos, validarlos y observarlos.
De “tareas” a “assets”: un ejemplo con datos clínicos
Imagina un pipeline diario: extraer pacientes, limpiar, y generar dos salidas (dashboard y modelo predictivo).
Enfoque tradicional — piensas en scripts:
extraer.py → limpiar.py → validar.py → exportar.pySi validar.py falla… ¿qué dato está corrupto? ¿Qué procesos downstream se rompen? Toca investigar.
Enfoque Dagster — piensas en los datos producidos:
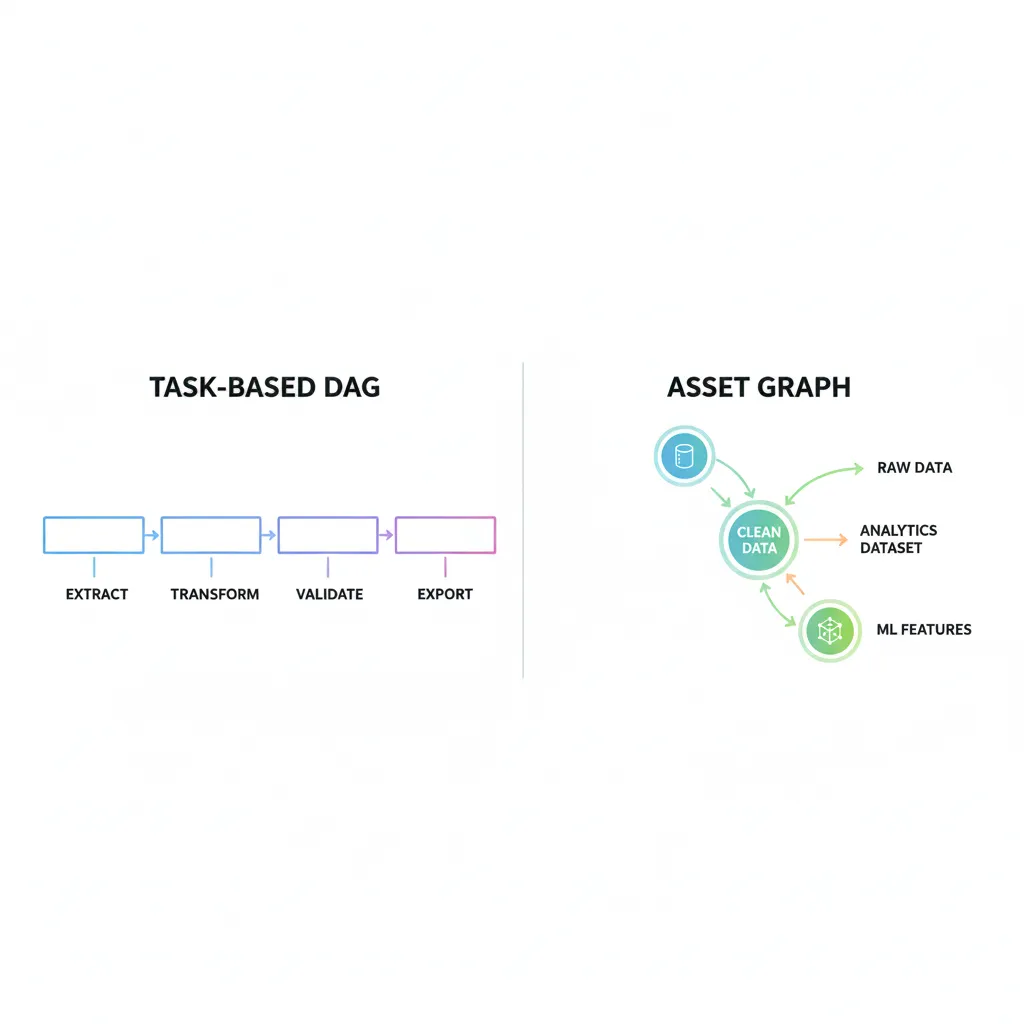
Ahora, si pacientes_clean falla:
- Ves inmediatamente en la UI qué asset tiene el problema
- Sabes que
dataset_analyticsyfeatures_mlestán afectados - Puedes re-materializar solo ese asset sin re-ejecutar todo
- Tienes lineage, documentación y etiquetas (por ejemplo, para datos sensibles) en un solo lugar
Lo que suele gustar de Dagster
1) Desarrollo local con fricción baja. Levantar un entorno con UI es rápido y orientado a iteración. Sin Docker obligatorio para empezar.
2) Asset checks: calidad dentro del flujo. Un “run exitoso” no significa “dato correcto”. Con checks puedes validar nulos, esquemas esperados y reglas de frescura.

3) UI útil para operar y depurar. Grafo de assets, ejecuciones, logs, particiones y re-materializaciones. Diseñada para ayudar, no solo para mostrar.
4) Encaja bien en stacks modernos (dbt + Python). Con dagster-dbt, tus modelos dbt se ven como assets dentro del grafo, conviviendo con transformaciones Python y artefactos de ML.
Comparativa rápida
| Herramienta | Cuándo encaja | Punto fuerte | Ojo con… |
|---|---|---|---|
| Dagster | ”Datos como producto”: lineage + calidad | DX y enfoque asset-first | Curva inicial + operación en prod |
| Airflow | Ecosistema masivo y operadores listos | Muy extendido y battle-tested | Modelo centrado en tareas; debugging áspero |
| Prefect | Flexibilidad y scripts → workflows | Muy cómodo en Python | Menos “opinión” sobre assets/lineage |
Manos a la obra (mini demo)
Flujo recomendado con create-dagster y el CLI dg:
uvx create-dagster@latest project mi_proyecto
cd mi_proyecto
source .venv/bin/activate
dg dev
# UI: http://localhost:3000Ejemplo de assets (en src/mi_proyecto/defs/assets.py):
import pandas as pd
import dagster as dg
@dg.asset(tags={"pii": "true"})
def pacientes_clean():
"""Limpia datos de pacientes."""
df = pd.read_csv("data/pacientes_raw.csv")
df = df.dropna(subset=["patient_id"])
df.to_csv("data/pacientes_clean.csv", index=False)
return len(df)
@dg.asset(deps=[pacientes_clean])
def reporte_estadisticas():
"""Genera un resumen a partir del CSV limpio."""
df = pd.read_csv("data/pacientes_clean.csv")
return {"total": len(df), "edad_media": float(df["age"].mean())}Nota sobre datos sensibles: Para clasificación (por ejemplo PII), usa tags. Para documentación rica (schema, links, etc.), usa metadata.
Trade-offs reales
- Curva de aprendizaje: el salto de tareas a assets requiere ajuste mental, aunque encaja rápido cuando el equipo piensa en datasets.
- Producción = arquitectura: webserver, daemon, almacenamiento de runs/logs, y CI/CD.
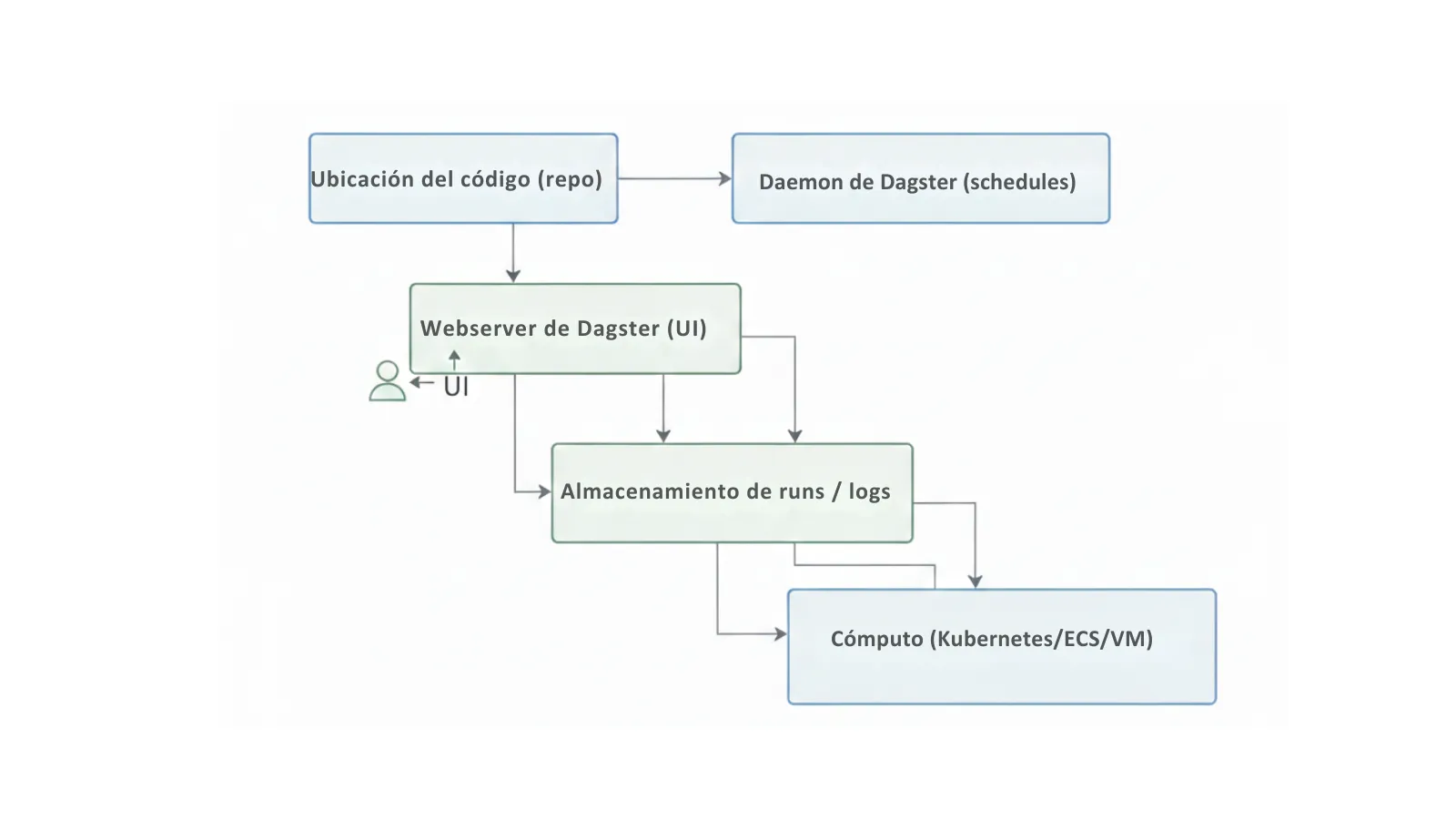
- Seguridad:
dg deves para desarrollo y no incluye autenticación ni cubre necesidades típicas de producción. Si autoalojas, necesitas diseñar tu estrategia (reverse proxy, SSO) o valorar Dagster+. - Ecosistema: Airflow sigue ganando en integraciones “legacy” y años de adopción.
OSS vs Dagster+
- Dagster (OSS): open source, autoalojado, sin coste de licencia. Ideal para empezar y construir.
- Dagster+: oferta managed con RBAC, SSO, SCIM y observabilidad avanzada. Pricing por créditos; mejor revisarlo en la web oficial.

¿Cuándo lo recomendaría?
Sí, si…
- Te importa la trazabilidad (lineage) y la calidad como parte del pipeline
- Combinas dbt + Python/ML y quieres un grafo unificado
- Valoras el developer experience: iteración local, debugging, testabilidad
Quizás no, si…
- Solo necesitas “un cron que ejecute un script”
- Tu orquestación actual funciona y no hay dolor real
Recursos
- Documentación: docs.dagster.io
- Quickstart: docs.dagster.io/getting-started/quickstart
- GitHub: github.com/dagster-io/dagster
- Dagster University: courses.dagster.io
Conclusión
Dagster vale la pena explorarlo, aunque no lo adoptes mañana en producción. El modelo mental de “assets” encaja especialmente bien para equipos que trabajan con ML, analytics complejos, o que necesitan observabilidad seria sobre sus datos.
Y lo mejor: es open source. Pruébalo gratis, rómpelo en local y decide por ti mismo.
Renata d’Almeida — Experta en Datos en Idara Health
“Sin datos solo eres otra persona con una opinión.” — W. Edwards Deming